
GraphQL’s Dark Secrets Revealed
GraphQL is everyone’s new trendy gem in the API world recently. And I hear the question ‘should I adopt’ so often that if I had a bit coin for each time someone said it, the market would have collapsed at least a couple times by now.
But for every person jumping on board the GraphQL train, they don’t realize everything they are going to have to do and going to have to give up in order to implement. Here are a few of my favorites all confirmed by GraphQL.org and the creator of GraphQL:
- GraphQL is a Layer on top of existing API’s : Thats right. All GraphQL implementations require an existing API implementation (see image below). They do not provide API’s for you. They just provide functionality ON TOP OFF your existing API’s. EVEN IF you are connecting to a database, that database does not understand HTTP protocol or have endpoints so it needs a business logic layer to build endpoints and make SQL calls separate from GraphQL which calls it.
NOTE: There IS an exception wherein GraphQL implementations use ‘resolvers’ (basically an ORM layer) that does ‘lazy-loading’ on a database. This acts as ‘dumb api’ in that there is no business logic; An api without business logic is just a database dump and leaves you open to data mining. This is why no one in their right mind does this.

- Additional Layer means additional processing: Oh doesn’t anyone tell you this? Since you now have to request your API’s through another layer (see image above), you now have another layer of processing to go through. This causes each API call to be increased by several milliseconds… in some cases DOUBLING THE TIME PER REQUEST!
- Schema stitching requires a separate request/response per endpoint: This should horrify you. When the client makes a SINGLE REQUEST and the backend does ‘schema stitching’, the backend has to do a redirect from each endpoint resulting in each request being dropped and reissued again and again and again and again. Their are open source api frameworks that can share the request/response through automated batching and API Chaining… but GraphQL implementations will always drop the thread and reissue the request over and over. Even the creator of GraphQL, Lee Byron, has stated:
“The GraphQL specification does not require a specific request/response pattern to backing data stores … Schema stitching is only one technique of many that some GraphQL users employ and I don’t advocate it personally. “
- Difficult to cache : When your queries consist of a mashup of queries, how are you supposed to cache this and what is the point. GraphQL’s nature makes it difficult to cache queries and so it makes your queries just a little slower as a result. If you want a cached query, you will find yourself default to using REST.
- No Rate Limiting: Want to do rate limiting on GraphQL. Tough luck. Ain’t gonna happen. The way GraphQL is built, you can’t do it… and least not to the incremental way that REST does. The best way that GraphQL vendors have been able to get to is limit to by ‘job’.
- GraphQL is NOT API Automation : While it is advertised as an automation solution, it is NOT ; there are API Automation Solutions but GraphQL is NOT ONE. Does it automatically handle batch api calls for you for all endpoints? Does it automatically handle webhooks for you for all endpoints? Can you autromatically do schema stitching for ANY ENDPOINT? The answer is no. Nothing is automated. You still have to write code (and redeploy your application) for everything you need.
- Benchmarks: Try looking at some of the GraphQL benchmarks sometime and look at what people brag about for numbers on a single machine with no security, validation, or anything else…vs what is actually possible for API Automation (see below):
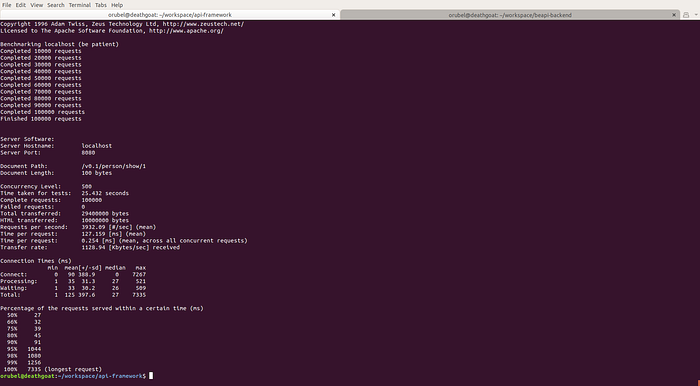
NOTE: Above are the stats on an api implementation handling auth/validation, CORS, localized caching, batching, webhooks, AND MORE! And it’s on the same machine as all the other resources (ie the database) and at greater than 3900/RPS,it still is blazingly faster than all other GraphQL implementations!
- Facebook patents : Thats right. Facebook has wasted no time patenting the technology. Facebook has a habit of offering things for free and then taking them back once they see they can make money. This has happened numerous times with the company in the last 5 years. Who knows how long it will be before you will be sued by this behemoth for using these technologies in your work?
Flames From GraphQL Fans
Some people say I’m wrong in this assessment. But in a recent survey done of 20,000 developers, this was the exact same assessment (and then some) of why people were not adopting GraphQL:

So Why Are People Adopting This?
Most aren’t (regardless of the hype you see). But for those who are, there are three reasons:
- GraphQL has a marketing arm: GraphQL was created by Facebook. Need I say more. There are open source api automation frameworks out there but they do not have Facebook promoting them.
- GraphQL is about convenience (not automation): GraphQL was never about automation of API’s but tried to tack on a solution after the fact with ‘schema stitching’. The original solution was all about creating a solution for presenting data regardless of whether it was JSON/XML/whatever… and this it does well.
- Hype without Understanding: Much like with the Ruby Hype of the early 2000’s, Hype was far greater than need (or scale and speed). Everyone talks about it so people evaluate and wonder if they need it. Some adoption is happening without even understanding what it is, whether they need it and without understanding the con’s of the product.
If you enjoyed this story, you may also enjoy additional reading about API’s and software development below:
